

































The rise of Large Language Models (LLMs)
Large Language Models are revolutionizing the way software developers work. Acting like powerful assistants, they can generate code from straightforward instructions and even convert code between different programming languages. They also excel at analyzing vast amounts of data to detect bugs or performance issues in real time. As a result, developers can accelerate their workflow, reduce time spent on repetitive tasks, and take on more complex projects with increased efficiency.
Introduction: Pioneering Reliable AI-Driven Development
At Juspay, we’re redefining software development for mission-critical systems like payment processing, where even the smallest error can disrupt transactions or erode trust. Our journey began with the AutoTranspiler—an ambitious tool originally built to convert a Haskell-based payment connector to Rust.
But the vision goes far beyond just Haskell and Rust. The Auto-Transpiler is a function-wise, semantics-preserving code intelligence system designed to translate code between any languages while ensuring behavior remains consistent across all execution paths and database interactions. It’s not just a transpiler—it’s a step toward a future where code is portable, tests are auto-generated, and language migrations are seamless and without being locked into a specific tech stack.
However, we encountered significant challenges: In the early days, the AutoTranspiler relied heavily on Large Language Models (LLMs) for code generation. Even today, we rely on LLMs extensively, but we use them wisely, creating supervised workflows to ensure reliability. These issues underscored the limitations of using LLMs alone—while they’re flexible and impressive, their non-deterministic nature made them unreliable for production-grade transformations. To address this, we developed a suite of LLM-powered frameworks that ensure compilable, verifiable, and correct code transformations.
The AutoTranspiler Journey: From Challenges to Solutions
Our goal was clear: convert a complex Haskell codebase to Rust while preserving every bit of business logic and ensuring the result was ready for production. In the beginning, AutoTranspiler leaned heavily on Large Language Models alone to generate the code. While promising, this approach quickly showed its limitations:
- Broken imports caused build failures.
- Missing or partial functions led to gaps in critical workflows.
- Syntax errors and type mismatches made the code non-compilable.
- Empty stubs replaced actual logic, and worse,
- Subtle bugs in business logic risked breaking real transactions.
These weren’t just technical hiccups—they were reminders that AI alone isn’t enough for production-grade systems.
To solve this, we built a suite of six tightly integrated frameworks, each designed to catch and fix a specific class of issue. Together, they form a powerful pipeline that turned the AutoTranspiler from an experimental tool into a production-ready solution. This pipeline ensures every line of code is correct, complete, and safe to ship
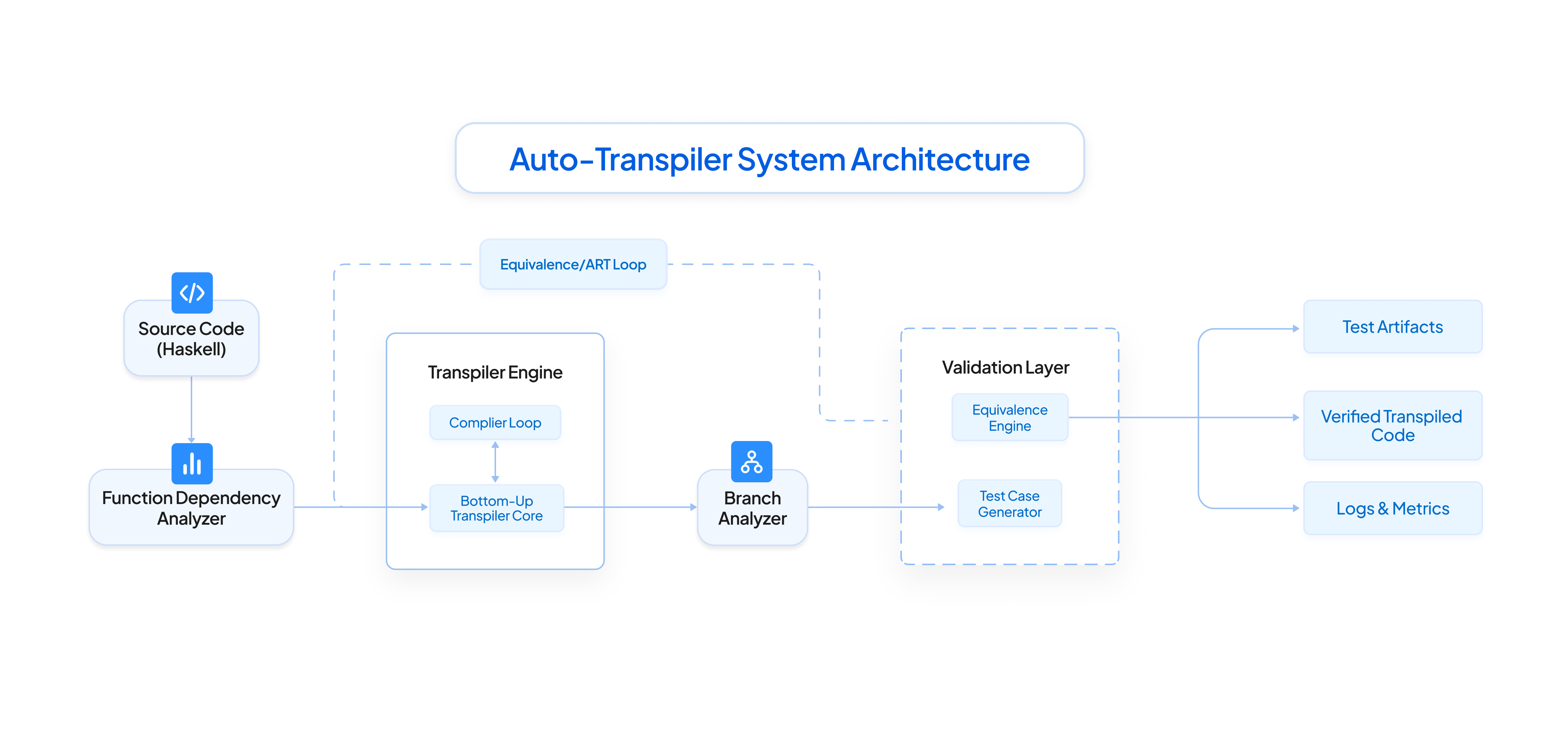
Core Frameworks for AutoTranspiler Excellence
Our code intelligence platform, powered by six specialized frameworks, tackles key challenges in the AutoTranspiler pipeline, enabling reliable and scalable Haskell-to-Rust code transformation for mission-critical systems like payment processing.
1. Branch Detection: Comprehensive Path Mapping
Purpose: Ensures no execution path is missed by identifying all control flows for exhaustive testing.
How It Works: Combines regex-based static analysis with LLM-driven insights to detect branches (e.g., if-statements, pattern matches) in functions. For example, in a payment function, it identifies distinct flows for UPI, card, or intent-based transactions. Tools like LSP and Tree-sitter enable cross-language compatibility for Haskell and Rust.
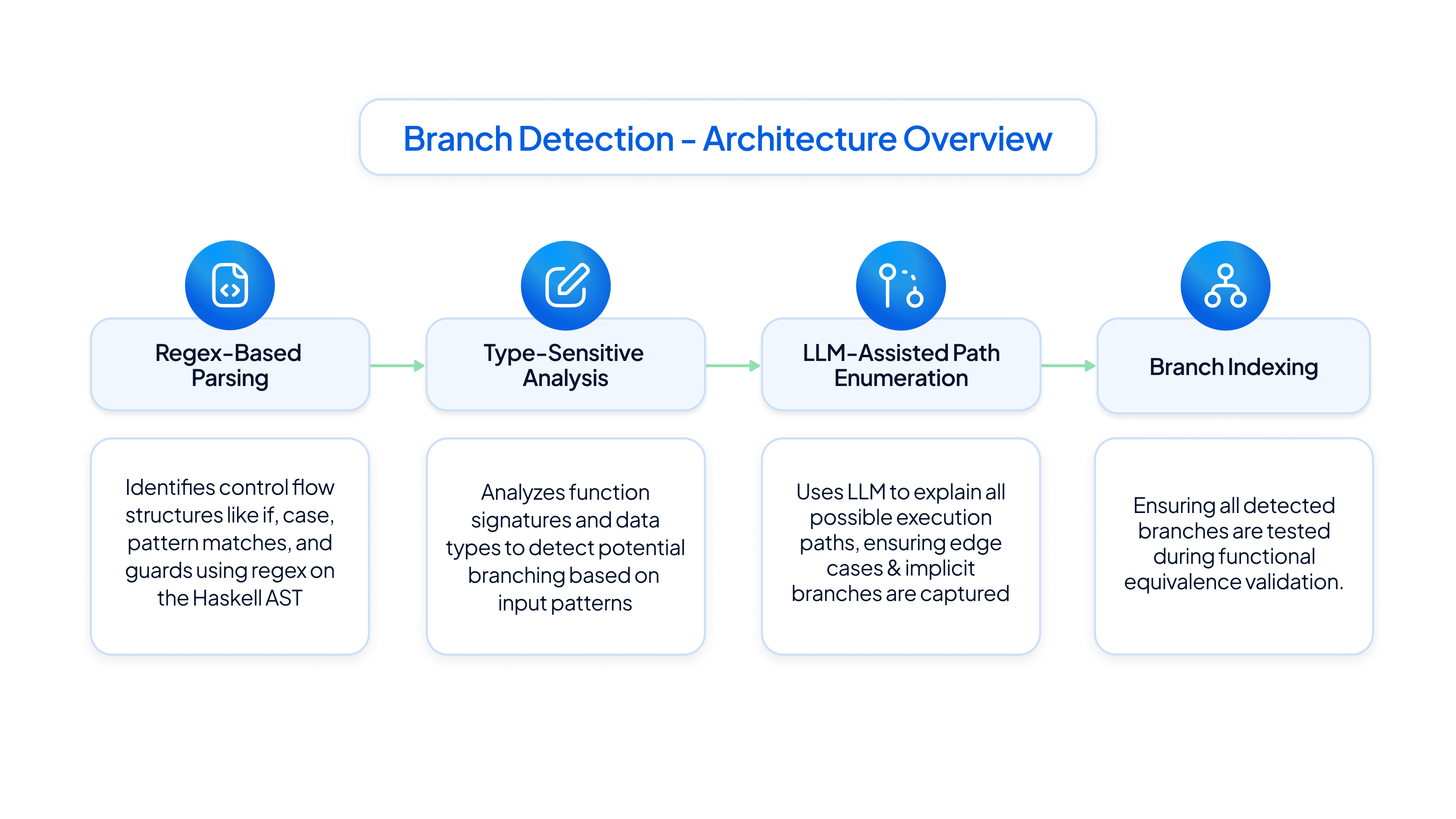
Technical Strengths:
- Scalability: Processes millions of branches efficiently.
- Precision: LLMs enhance regex to capture complex control flows.
- Integration: Works across languages using structured code analysis.
AutoTranspiler Impact: Mapped over 10,000 control paths across 1,100 functions, ensuring complete coverage during transpilation.
Caught edge cases like invalid merchant inputs (e.g., negative amounts) and InvalidHexString values (e.g., "zz12gh"), preventing transaction failures and decoding errors in production.
2. Test Case Generation: Exhaustive Automated Testing
Purpose: Generates comprehensive test cases to cover all branches, addressing non-compilable or incorrect code.
How It Works: Uses branch detection outputs to create structured JSON test cases based on function signatures and control paths. Leaf functions undergo direct input/output testing, while node functions use mocked dependencies. It generates more test cases than branches (e.g., 40+ cases for 30 branches) to cover edge cases like null or out-of-range inputs.
Technical Strengths:
- In-depth Coverage - Achieves extensive branch coverage with high reliability.
- Automation: Eliminates manual test creation.
- Structured Output: JSON format integrates with Haskell and Rust test environments.
AutoTranspiler Impact: Generated over 50,000 test cases, identifying errors during Haskell-to-Rust conversion.
Example: Detected and resolved issues like null input errors, reducing post-transpilation debugging time.
3. Functional Equivalence: Preserving Code Behavior
Purpose: Verifies that transpiled Rust code behaves identically to the original Haskell code, addressing business logic errors or missed functions.
How It Works:
- Step 1: Inject Inputs
Generate inputs from function signatures and branching paths to test both Haskell and Rust implementations under identical conditions. - Step 2: Child Function Input Matching
Test child functions independently for input-to-output behavior, ignoring execution order and focusing on valid functions. - Step 3: Mock Functions for Child Behavior
Mock child functions to control outputs, comparing inputs received in Haskell and Rust; mark mismatches as non-equivalent. - Step 4: Output Comparison
Compare final outputs in normalized formats, mapping Option/Result types gracefully between Haskell and Rust. - Step 5: Error Alignment, Log Differences
Log runtime errors, panics, and missing branches; record mismatches in inputs, outputs, and function calls for automated fixes and RCA.
This assumes child functions are behaviorally equivalent, focusing on parent logic comparison.
Technical Strengths:
- Cross-Language Validation: Ensures Haskell-to-Rust consistency.
- Comprehensive Checks: Validates outputs and control flows.
- Iterative Fixes: Automates error resolution.
AutoTranspiler Impact: Confirmed equivalence for over 1,000 functions, ensuring Rust code preserved Haskell logic.
Example: Corrected logic discrepancies in payment processing flows, maintaining transaction integrity.
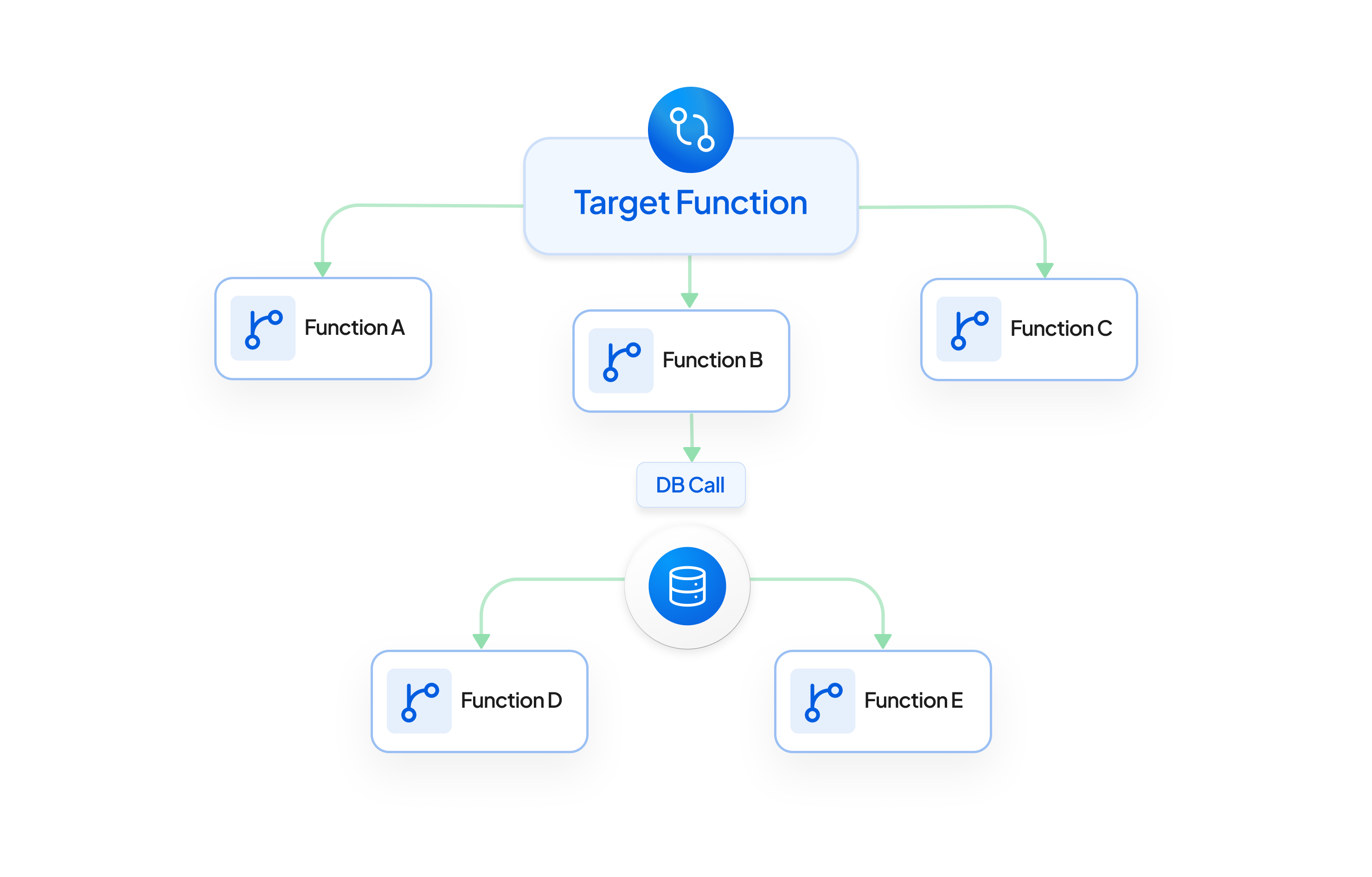
4. Function-Level DB Dependency: Tracking Database Interactions
Purpose: Prevents transaction failures by identifying and mapping database dependencies to analyze their impact on functions, APIs, and transaction flows.
How It Works: Analyzes database calls within functions and their sub-functions, building a dependency graph to map affected flows. For example, in a transaction gateway, it traces paths from a central module (e.g., CommonGateway) to database interactions.
Technical Strengths:
- Granular Analysis: Maps dependencies at the function level.
- Scalability: Handles complex DB interactions in large codebases.
- Proactive Detection: Flags dependencies before schema changes cause issues.
AutoTranspiler Impact: Enabled identification of functions affected by database schema changes, ensuring stable Rust code by mapping dependencies.
Example: Prevented transaction disruptions during a merchant’s database update by identifying affected functions and flows, such as when adding a card bin to a gateway.
5. Function Profiling: Contextualizing Function Roles
Purpose: Enhances transpilation accuracy by providing context, addressing empty or incorrect code.
How It Works: Analyzes a function’s behavior (“What”) and usage (“Where”) using dependency graphs. Bottom-up analysis summarizes operations and sub-function interactions, while top-down analysis identifies the function’s role in broader workflows. Outputs are concise natural language summaries.
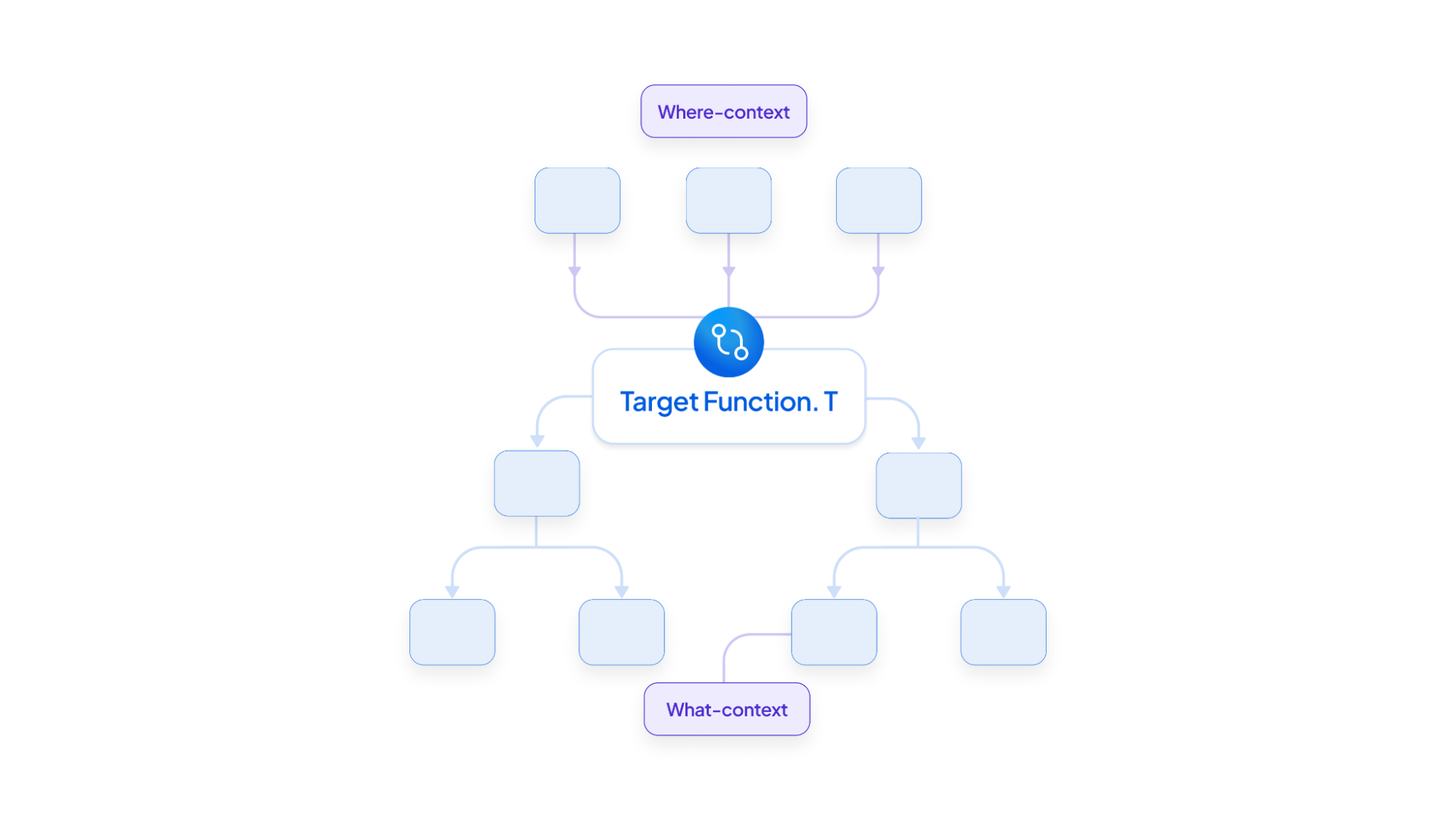
Technical Strengths:
- Holistic Insights: Combines bottom-up and top-down perspectives.
- Developer-Friendly: Summaries simplify onboarding and debugging.
- LLM Enhancement: Improves prompt accuracy for code generation.
AutoTranspiler Impact: Provided summaries like “Processes UPI transactions, validates inputs, and calls a DB function; used in checkout flow,” guiding precise Rust transpilation.
Example: Clarified function purposes, accelerating debugging and code alignment.
6. Haskell Code Refactoring: Streamlining Code Transformation
Purpose: Prepares Haskell code for Rust compatibility, addressing non-compilable code and incorrect imports.
How It Works: It uses Haskell-tools to manipulate Abstract Syntax Trees (ASTs) for targeted changes, such as renaming types or restructuring code. Every module can be represented as an AST, provided it can be successfully parsed. By utilizing tools that expose and manipulate the AST, specific elements like functions, type declarations, or signatures can be located via pattern matching. Once a relevant portion of the AST is located, it can be modified as needed, and then the source code is regenerated from the updated AST. This approach is particularly useful for applying consistent changes across many modules in a large codebase. For instance, standard Haskell AST manipulation tools can be combined with dependency analysis tools like fDep to perform targeted modifications within a specific flow.
Technical Strengths:
- Deterministic Output: Ensures compilable, semantically equivalent code.
- Scalability: Applies changes across large repositories.
- Cross-Language Support: Facilitates Haskell-to-Rust transitions.
AutoTranspiler Impact: Restructured over 500 Haskell functions, enhancing clarity and testability.
Example: Simplified codebase architecture for seamless transpilation.
AutoTranspiler Pipeline: A Proven Success
The Haskell-to-Rust pipeline achieved over 90% success, transpiling 1,000+ functions with minimal manual effort. The process involved:
- Mapping 10,000+ control paths via branch detection.
- Generating 50,000+ test cases for full coverage.
- Transpiling with LLM prompts enhanced by function profiling.
- Verifying equivalence and resolving errors iteratively.
This delivered a production-ready Rust connector, demonstrating reliability in critical systems.
Why Our Frameworks Stand Out
- Granular Focus: Function-level analysis ensures precise Haskell-to-Rust transpilation, e.g., mapping UPI transaction paths accurately, catching edge cases like invalid inputs.
- Structured Context: Dependency graphs and ASTs enhance LLM reliability by mapping function interactions and enabling deterministic refactoring for robust Rust code.
- Comprehensive Testing: Automated test cases cover all branches, ensuring error-free payment systems via thorough validation.
- Scalability: Manages large codebases with extensive branches using LSP and Tree-sitter for cross-language support.
- Automation: LLM-driven fixes resolve errors iteratively, minimizing manual effort in transpilation.
Future Innovations
Our AI Center of Excellence is developing:
- Code Optimizer: Improves the efficiency of code by optimizing latency and resource usage, ensuring high-performance implementations for time-sensitive systems.
- Auto RCA: Accelerates debugging by tracing issues in production or development to their origins, whether in code, database changes, or configurations, minimizing downtime in critical systems.
- Genius Bot: An intelligent assistant that answers domain-specific and analytics queries, traces config impacts, explains success rate drops, latency spikes, and other transaction anomalies.
- Feature/Impact Analysis: Analyzes code and configuration changes to identify affected flows and database calls, flagging high-risk areas for prioritized testing and review.
- Business Compiler: Transforms technical docs into pre-filled pull requests with linked files, change highlights, and summaries—boosting developer productivity 10x.