





























Juspay is a leading multinational payments technology company, powering superior conversion rates, seamless customer experiences, cost optimization, and fraud reduction at scale for 500+ top global enterprises and banks. Founded in 2012, the company processes over 300 million daily transactions, exceeding an annualized total payment volume (TPV) of $1 trillion with 99.999% reliability. Headquartered in Bangalore, India, Juspay’s global network of 1200+ payment experts operates across San Francisco, Dublin, São Paulo, and Singapore.
_
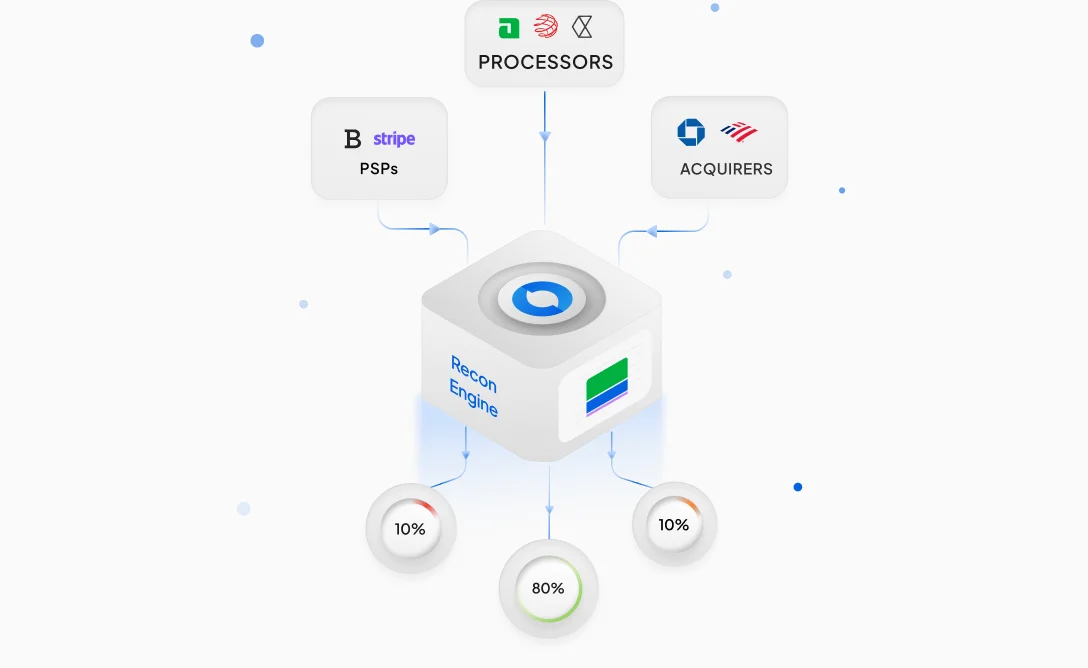
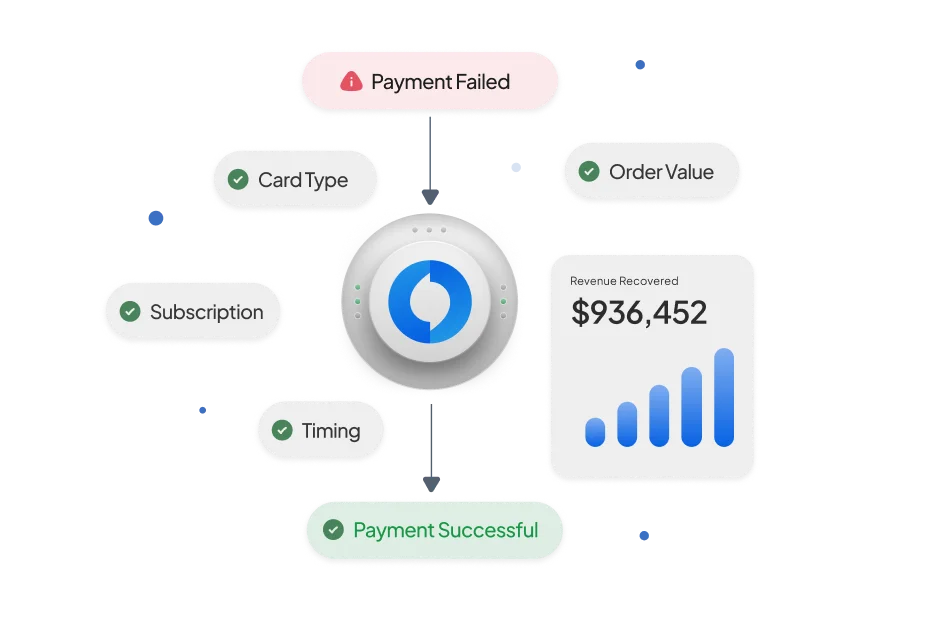
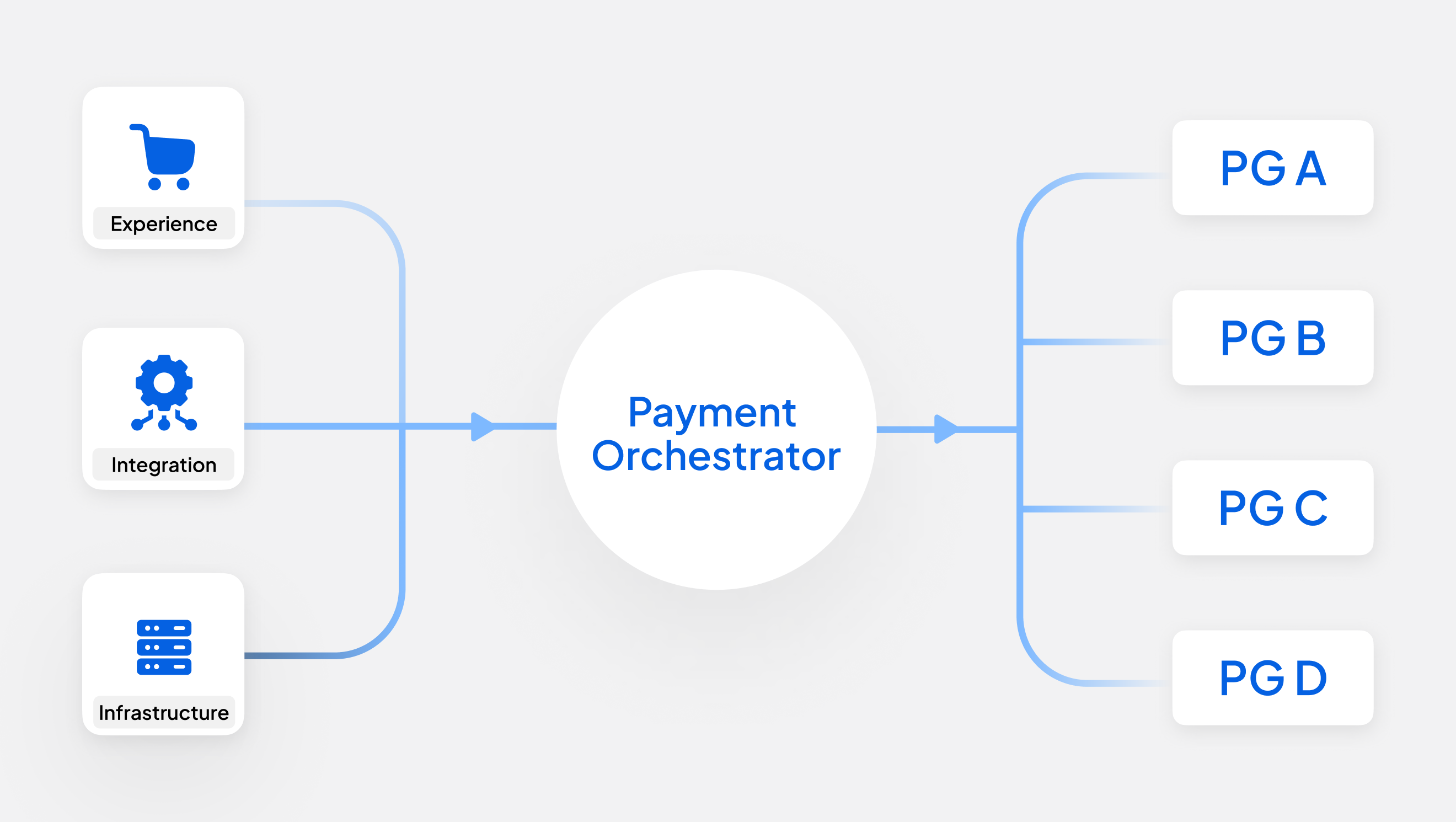
Juspay offers a modular and interoperable product suite for merchants that includes open-source payment orchestration, seamless authentication, payment tokenization, fraud & risk management, global payouts, end-to-end reconciliation, unified payment analytics, and more. For banks, Juspay’s offerings include end-to-end white label payment gateway solutions & real-time payments infrastructure._
We need a design that guarantees High-Availability of five-nines! A distributed, fault-tolerant system with state of art engineering techniques, spanning across multiple DCs in Active-Active mode is an absolute necessity.
The Challenge
Building Distributed systems at this scale is still an Art. While there are standard open-source building blocks available, the right architecture or the way to combine the components needs creativity and deep first-principles understanding. It also takes wisdom to make the right trade offs combining product/domain expertise with engineering excellence.
.What you’ll be working on
At the core, we are an engineering-focused organization with heavy investments in pure
functional programming techniques and distributed system architectures. We use Haskell for backend development, we have invested in one of the fastest real-time data streaming
technologies, we created our own polyglot database management system called DBMesh.
We are establishing a team to upgrade our system architecture to scale to 10X our current
volume and support the high-reliability needs with a multi-region DC Active-Active architecture.
Some of the current projects in our distributed systems team:
● Designing our architecture to work active-active across DCs with intelligent SDK and gateway proxies to route traffic between them.
● Moving to an LSM engine based distributed DB that spans across datacenter regions ● Service mesh architecture that provides failover across Kubernetes clusters ● Event sourcing and Event-mesh architecture to move all operations outside the critical path to a reliable async mechanism.
● A multi-DC + client-side distributed data caching system and ensuring strong eventual consistency.
● Automatic anomaly detection system with streaming data streams across varied systems ● Build unified SRE systems to manage multiple stacks across DCs and Banks.
The Learning track
Our teams are mostly built with freshers - smart, vibrant, hardworking. We need a fast track learning process for them to understand the deep principles of distributed systems and also get accelerated hands-on experiential learning
Design from Scratch: Design from first principles a system that will support India’s scale and learn from Biology how to keep it healthy and hale! We are creating an internal school for distributed systems to fast track the first principles learning process.
Make Production your Playground: Not just design but Play around with the systems esp. With modern Chaos testing approaches. Discover, fix, and ensure the system’s capability to withstand unexpected scenarios.
Join the Team
Our systems team has taken up this huge responsibility to concretize the vision to scale up to 50M txns/day. We are looking for deep systems thinkers and high problem-solvers.
System Builders: You think from first principles and understand/want to understand how things work deeply
Chaos Engineers: What’s the best way to ensure that systems are resilient? Let’s bring them down!! (Check out chaos engineering @ Netflix)
Responsible SREs: Can you be confident that the systems you designed and played around with will never go down??
Do you resonate with any of the above? You may be just the right person for the team




