






























Last year we shipped Genius, a conversational interface on the Juspay portal that lets merchant teams query payments data in simple, natural language. Instead of writing SQL or requesting a dashboard build, teams type in a question and get answers they can act on.
In the last three months, users across 500+ merchants have had conversations with Genius. But the core engineering challenge was never the chat interface. It was ensuring the answers were trustworthy enough for operational decision-making.
A conversational payment intelligence agent that returns a wrong number confidently is worse than no agent. When someone asks "what was our UPI success rate yesterday" and the answer flows into a standup, a merchant escalation, or a review with leadership, being wrong has a cost - and the user often has no way to tell.
This post is about what sits underneath Genius: the execution layer we built to make an LLM-driven payment intelligence agent reliable in production. We employ agent harness: the set of engineering principles and system-level guardrails that make a conversational payment intelligence agent reliable enough for enterprise scale.
What Is an Agent Harness?
An LLM isn't an agent. It's a component that can reason, call functions, and produce text. Turning it into a production system takes infrastructure that controls the execution loop:
- Restricts model context and access
- Validates intermediate outputs
- Enforces deterministic boundaries
- Captures traces for observability and debugging
This surrounding infrastructure is the agent harness.
Concretely: when a user asks "What was our UPI success rate yesterday?," the harness decides which schema the model sees, validates every field name before a query fires, translates system codes back to human-readable names in the response, and logs the entire chain for debugging.
The Core Tension
LLMs are good at understanding the question but struggle with domain specificity: especially with years of schema decisions with legacy field names, internal codes, and overloaded terminology.
Payments are particularly unforgiving here. Schema field names are legacy identifiers. Filter values are system codes that look nothing like what a user would type - "netbanking" is stored as NB, "UPI intent" as UPI_PAY, while "SR" is interpreted as success rate in payments and service requests in CRM. And because the numbers flow into operational decisions, "usually correct" isn't a viable bar.
We hit every one of these failure modes in the first few months of running Genius in production. Before getting into them, two architectural decisions shaped everything that followed.
Two Foundational Decisions
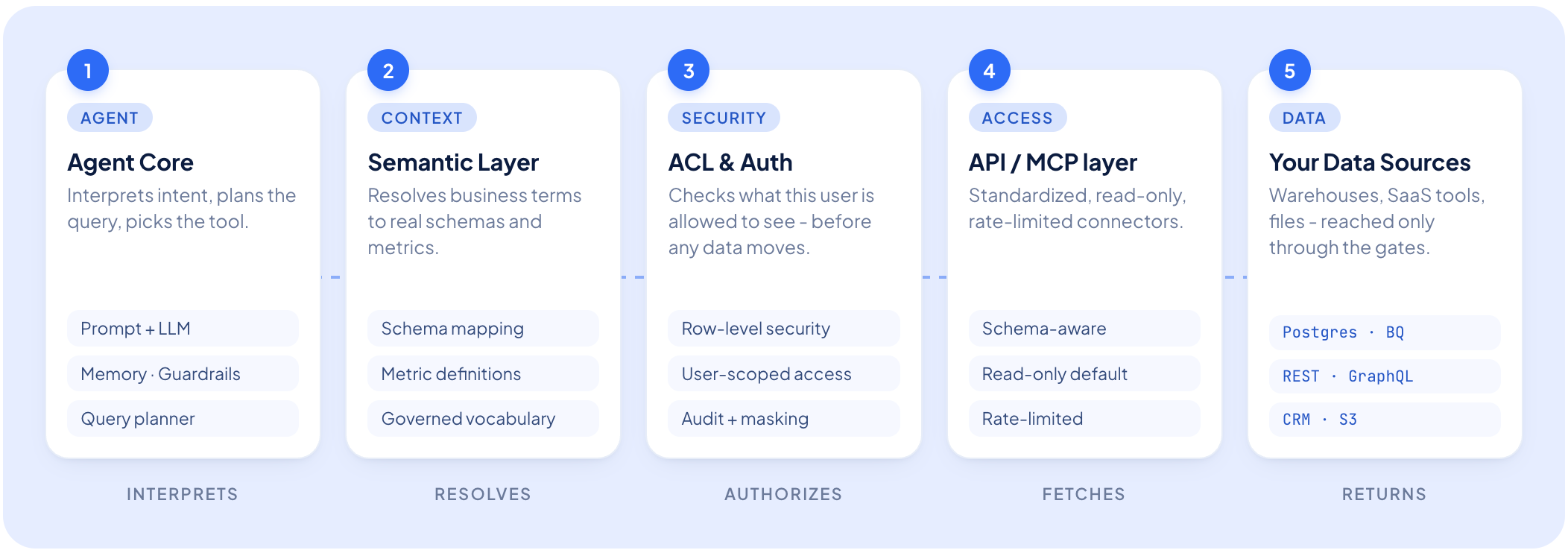
1. The agent never touches the database
Most text-to-SQL demos allow LLMs to generate a SQL query and run it directly. While that’s acceptable for a demo, it's a liability in production.
From day one, Genius interacts with data through a permission-aware API layer. The agent expresses an intent - metrics, filters, time window - and the API layer translates that intent into a query, enforces access controls, and returns results.
The LLM never:
- Sees connection strings
- Generates raw SQL
- Decides access scope
This has a few downstream effects. Cross-merchant data leakage is structurally prevented: even if the model were manipulated into requesting another merchant's data, the API layer would reject it. Query execution stays deterministic: the layer knows how to join tables, which timestamp column to use, and how to apply data category-specific filters. And schema changes don't break the agent - when underlying tables evolve, the API layer absorbs the change and the agent's interface stays stable.
2. Access control is deterministic, not probabilistic
We never authorize the LLM to decide whether a user should be allowed to see certain data. That decision is made by infrastructure.
Every API call the agent makes runs on the requesting user's own scoped session token, bound to a specific merchant at login. The model holds no credentials and cannot override access controls.
This matters especially in a multi-agent setup. When one agent hands off to another - say, from an analytics query to a deeper SR-drop investigation - the scope travels with the handoff. There's no step in the pipeline where scoping information is dropped and could be replaced by something else.
Problem 1: Hallucinated Fields and Phantom Filter Values
This was the most common failure mode in early Genius, and the most insidious because it looked like a correct response.
Hallucinated field names
When asked "Show me UPI transactions by bank," the agent might filter on 'bank' - a field that sounds reasonable but doesn't exist. The actual field is issuer_bank. The query returns empty results. The agent reports "no transactions found," with nothing in the response signalling that the query itself was malformed. In the early weeks, roughly one in three complex queries silently failed this way.
The fix: Mandatory schema grounding.Before constructing a query, the agent retrieves:
- Valid metrics
- Valid dimensions
- Allowed filter values
- Time column
- Lookback constraints
Fields outside the schema are rejected pre-execution. Agent picks the right data category and builds against a confirmed schema.

Hallucinated filter values
Even when field names were correct, the LLM would guess at valid values for enum-type filters. A user asks about "netbanking" transactions. The system code is "NB." The agent passes "netbanking" as the filter value. The query returns zero results. The agent confidently reports there were no netbanking transactions - which is wrong, and sounds authoritative enough that the user has no reason to question it.
The fix: Pre-query value lookup. Before any query with an enum-like filter, the agent runs a fuzzy search against the live value set for that field. The user writes "netbanking"; the lookup returns the canonical code.
One nuance worth mentioning: not all fields warrant this lookup. For high-cardinality free-form fields like order IDs, request IDs, or refund amounts, fuzzy matching is meaningless and expensive. The system detects field cardinality and skips the lookup where it would just add latency. Getting this heuristic right took several iterations.
{
"input": {
"data_category": "payments",
"requests": [
{
"dimension": "payment_method_type",
"queries": [
"UPI"
]
}
]
},
"output": {
"dimension": "payment_method_type",
"results": [
[
{
"value": "UPI_PAY",
"confidence": 0.9
},
{
"value": "CARD",
"confidence": 0.2
},
{
"value": "WALLET",
"confidence": 0.15
},
{
"value": "NB",
"confidence": 0.08
}
]
]
}
}

Problem 2: Payments Terminology Is Ambiguous
Payments vocabulary is specialised and deeply overloaded.
For example,"SR" → success rate or service requests
"settlement" → merchant, bank, or dispute settlement
"volume" → count or value
When the LLM picked the wrong interpretation, it would construct a query that returned technically valid but semantically wrong results - and nothing in the response would flag the mismatch.

The fix: A data category-aware glossary injected at query time.
We built a glossary of Juspay-specific terms, acronyms, and concepts, with definitions scoped to each data category. At query time, the agent runs a semantic search over the glossary and pulls the relevant definitions into its context before reasoning. The definitions for a given term are specific to the active data category— payments, refunds, or mandates—and are not drawn from a single, universal dictionary. In other words, a term's meaning is category-sensitive.There's also a merchant-level layer on top of this. Different merchant teams develop their own shorthand over time - a word that means one thing at an ecommerce business might mean something slightly different at a fintech. When a team consistently uses a particular synonym, we capture that preference and the glossary respects it. Over time, each merchant's shorthand gets captured, so the glossary adapts to how their team actually talks.
{
"term": "upi_autopay",
"category": "Data Lookup Instruction",
"definition": "UPI AutoPay refers to subscription transactions using UPI autopay method for recurring payments. This enables automatic deduction from customer UPI accounts at regular intervals without manual intervention.",
"domain_context":{ "filtering_logic": "Use payment_method_type=UPI AND order_type IN (SUBSCRIPTION_EXECUTE, SUBSCRIPTION_REGISTER) for complete UPI autopay coverage "},
"synonyms": ["UPI autopay","UPI_AUTOPAY"]
}

Problem 3: The Agent and the Database Speak Different Languages
The agent operates in human vocabulary, while the database uses system identifiers. Bridging this gap proved more complex than expected.
"GMV," "revenue," and "sales" are three ways merchants refer to the same thing - but the underlying field is called total_amount. "Network" is how everyone talks about card processors, but the actual field name in the database is card_brand. And it goes further: "netbanking" is a payment method everyone recognises, but the system stores it as "NB." "UPI intent" becomes "UPI_PAY." A payment method called Pluxee is stored as Sodexo,its pre-rebrand name.
None of this is visible to users. But without a translation layer, each of these mismatches produces a silent failure.

The fix: A bidirectional alias layer. We built a system to prevent confusion during multi-turn conversations, especially when the agent is mid-reasoning on follow-up questions, we implemented a name-translation system. This system translates the user-facing names in a query to the agent's internal system names before dispatch, and then reverses the translation on the response. This ensures the agent consistently interacts with the original names it uses.
METRIC_ALIASES: Dict[str, str] = {
"revenue": "gmv",
"sales": "gmv",
"gmv": "gmv",
"total_amount": "processed_amt"
}
This reverse translation matters especially more in multi-turn conversations. If the agent asks about "netbanking" and the database returns results labelled "NB," the model now has two names for the same thing in its context window. On the next turn, when the user says "break that down by bank," the model has to figure out that "NB" from the previous response is the same thing as "netbanking" from the original question.
In practice, it doesn't - it starts generating filters using both terms interchangeably, producing queries that either fail or double-count. By translating system names back to human names before the model ever sees the response, we keep the context window clean. The model only ever works with one vocabulary: the user's.

A key complexity is that the same alias may map to different fields depending on the data category. For instance, the alias "status" corresponds to order_status in the payments data category, but to payout_status in the payouts category.
To handle this, the alias layer is designed to be data category-aware. Instead of relying on a single global dictionary, it uses the active data category to select and dispatch to the correct, category-specific translation table.
Problem 4: One Agent Can't Do Everything
In its early stages, Genius was a single agent handling everything from analytics, investigation, customer communication, to routing configuration, in one context window. As scope expanded, this broke down. No individual task was beyond the model; one context trying to serve all of them served none of them well. Improving one capability would degrade another.
The fix: Decomposition by responsibility. Today, Genius runs four sub-agents in production, each with one job.
Genius now runs multiple specialized agents:
- Payment Insights
- SR-drop investigation
- Routing rule management
- Payment failure investigation
When a task requires more than one, an orchestrator sequences them and passes outputs along the chain.
Failures stay contained, improvements stay targeted, and new capabilities slot in as new agents without touching what already works.
Making Accuracy Measurable
Identifying the above problems and developing solutions for them does not matter if we cannot measure success. Initially, accuracy validation was manual - someone checking answers against a dashboard. This approach is not scalable
We implemented the LLM-as-a-judge pattern for continuous quality monitoring. A secondary agent evaluates each session independently and produces a structured verdict, along with reasoning:
- Outputs structured verdicts: CORRECT, PARTIALLY_CORRECT, or INCORRECT
- Provides justification for the assigned score
- Flags low-scoring sessions for prioritized human review
The key is role separation: the primary agent is instructed to be thorough and helpful; the judge is instructed to be a skeptic. Splitting those roles produces better evaluation than asking the generator to assess its own output.
The same evaluation logic runs against a curated golden dataset - representative queries paired with known-correct answers - on every code and prompt change. If an edit intended to improve one query class silently degrades another, the golden dataset catches it before it ships. Live scoring reflects real usage; the golden dataset reflects controlled benchmarks. Both matter, and they catch different things.
For automated scoring, outputs are graded as CORRECT, PARTIALLY_CORRECT, or INCORRECT - turning accuracy from a qualitative gut-check into a trackable metric you can alert on and correlate with specific changes.
Making Every Decision Traceable
Every query is traced end-to-end: the system prompt active at execution time, every data call with its input and output, token counts and latency per step, and the final response with quality scores attached. Debugging a specific failure went from hours to minutes.
Prompts aren't embedded in source code - they're fetched at runtime from a centralized store, with every invocation recording which version was active. A prompt change doesn't require a deployment; rolling one back is a configuration change. When a quality regression surfaces, we can pinpoint exactly which prompt version was active when failures spiked.
User feedback flows directly into this loop: a flagged answer traces back to the exact reasoning chain that produced it, informing the next round of prompt improvement..
Where This Goes Next
Genius started as a way for merchant teams to ask questions about payments data. While that is still core, we've extended the same architecture into something broader: a support agent for Juspay merchants that goes beyond analytics.
A merchant hits a payment failure they can't explain — the agent investigates it end-to-end. An integration isn't behaving as expected — the agent diagnoses it. A routing configuration needs to be understood or adjusted — the agent handles it. A bug surfaces in production — the agent does the RCA. The goal is a single conversational interface that can answer most questions a merchant has about their Juspay integration without routing through a human specialist.
The same runtime underpins all of this - the permission-aware API layer, schema grounding, the alias layer, multi-agent decomposition, continuous evaluation. What changes is the surface area: instead of answering "what was our UPI success rate yesterday," the agent needs to reason across transaction logs, configuration state, integration history, and known failure patterns simultaneously.
This shifts Genius from a conversational analytics tool to an operational copilot for merchant teams. We’ll break down the engineering behind this in a separate post soon.