






























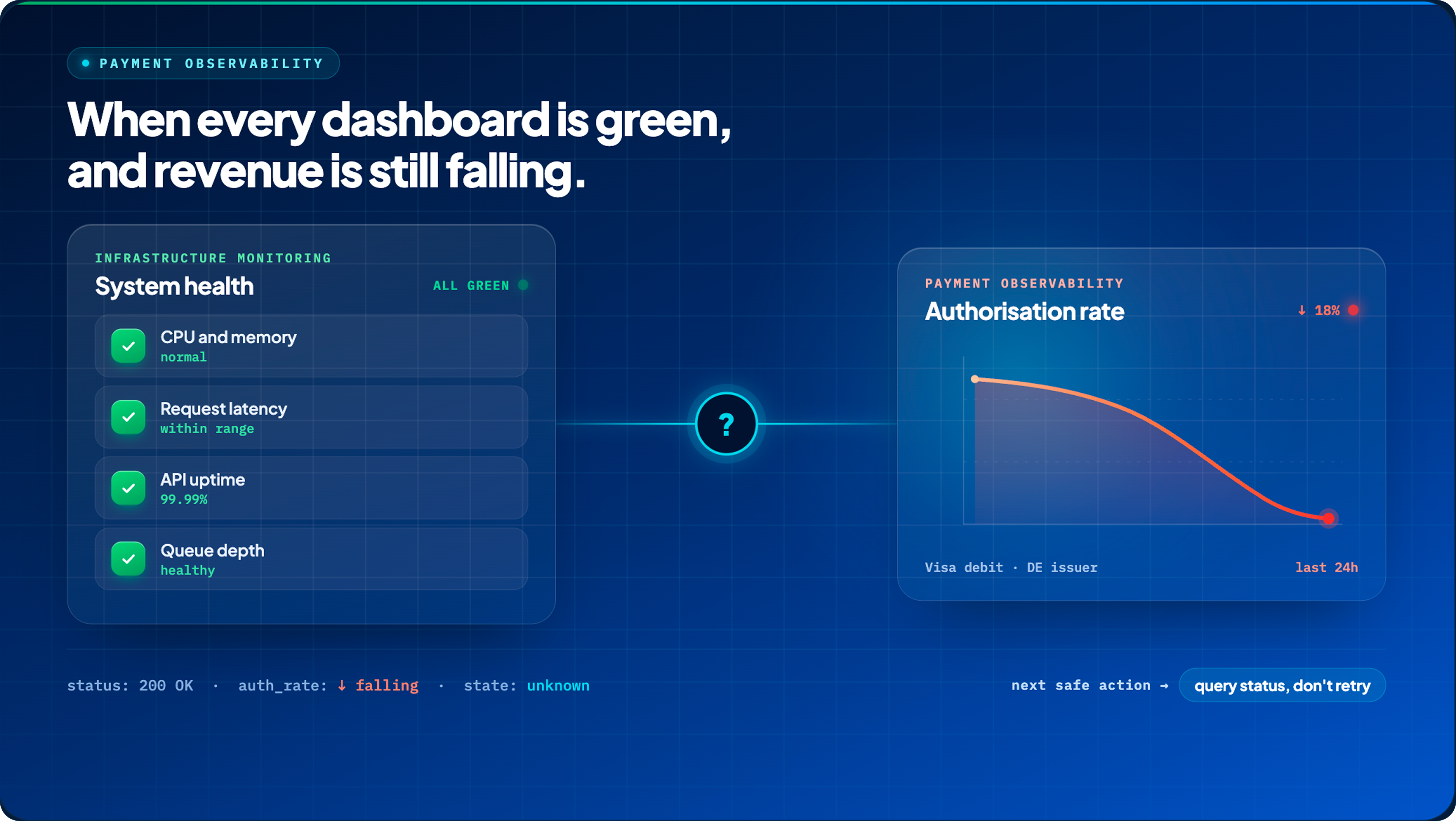
TL;DR: Payment observability is not the same as infrastructure monitoring. Your servers being up does not mean your payments are working. When a checkout times out, it is not a confirmed failure. The PSP may have already authorised the transaction, and retrying it without checking can charge the customer twice. Because every provider uses its own error vocabulary, raw responses must be preserved and translated into a shared model before they can be compared or acted on. Ultimately, a useful observability system answers one question above all others: what is the safe next action for this payment, right now?
Payment failures that infrastructure monitoring cannot see are the most expensive kind. Authorisation rates can fall while every server metric looks normal. A specific issuer segment silently starts refusing transactions while latency dashboards stay green. A checkout times out and the operations team marks the payment as failed. Meanwhile, downstream, the PSP may have already authorized it.
The problem is not a lack of data. Merchants running multiple PSPs generate more payment telemetry than most teams can process. The problem is that general-purpose observability tools are built around service health indicators like CPU, memory, and request latency. Because of this, they have no concept of what a payment is, what state it is in, or whether a particular failure is recoverable. They can tell you a server is slow. They cannot tell you whether your authorisation rate has quietly dropped for Visa debit cards issued in Germany.
Payment observability closes that gap. It is the capability to reconstruct a payment across every system that touched it, translate each provider's response into a shared business language, detect failure patterns by segment, and determine the safest next action. That is a fundamentally different problem from keeping your infrastructure healthy.
What is payment observability?
Payment observability is the ability to explain the state and outcome of an individual payment, and then connect that evidence to broader failure patterns across providers, payment methods, customer journeys, and markets.
Payment observability uses the same basic technical tools as general observability, such as logs, metrics, and traces from OpenTelemetry. However, it adds special features specifically for tracking money. It follows the exact steps a payment takes, understands the meaning of different bank error codes, and connects a customer's order to every payment attempt. Most importantly, it can tell the difference between a payment that has completely failed and one that is just waiting for a result.
A useful payment observability system should be able to answer these questions for any given transaction:
- What state are the order, payment, and each individual attempt in?
- Which stage in the payment journey produced the failure signal?
- What raw response did the provider return, and how was it interpreted?
- How confident is that interpretation?
- Did the failure affect a specific PSP, issuer, payment method, market, or channel?
- Is this problem isolated to one transaction, or is it happening across a segment?
- Should the system wait, query status, retry, reroute, trigger authentication, ask for corrected data, or stop entirely?
The last question matters most. An observability system that only finds clues but does not help you make a choice is not very useful. The goal is not just to see what went wrong. The goal is to understand the problem so you can fix it safely and know exactly what action to take.
How is payment observability different from infrastructure monitoring and reconciliation?
Infrastructure monitoring and payment observability are often conflated, and that conflation causes real operational mistakes. These two systems measure entirely different things, answer different questions, and operate on completely different timeframes.
| Capability | Infrastructure Monitoring | Payment Observability | Payment Analytics | Financial Reconciliation |
| Main Object | Technical components: Monitors the health of servers, hosts, API endpoints, and queues. | Individual transactions: Tracks the unique journey of each order, payment, attempt, and event. | Aggregated data: Examines groups of transactions by cohort, user segment, or market. | Financial data: Focuses on the 'source of truth' via ledgers, settlements, and bank records. |
| Typical Signals | System health: CPU usage, memory, latency, error rates, and queue depths. | Lifecycle data: Provider error codes, payment states, stage-level latency, and retry events. | Business trends: Conversion rates, authorisation percentages, and comparative volume mix. | Financial flow: Capture amounts, settled funds, fee structures, refunds, and bank disputes. |
| Primary Question | Is the system healthy? Checks if the underlying infrastructure is functioning. | Why did it fail, and what's next? Diagnoses specific failures to determine safe recovery actions. | Where is performance changing? Identifies broad shifts or trends in business metrics. | Did funds match records? Ensures that accounting books align with actual bank activity. |
| Time Horizon | Seconds to minutes: Focused on real-time alerting for immediate technical issues. | Real-time to resolution: Operates alongside the payment lifecycle to enable immediate action. | Minutes to weeks: Analyzes historical data to identify longer-term patterns and insights. | Hours to days: Batch-processed to ensure accuracy after transactions have settled. |
| Typical Output | Technical incident: Alerts on outages or performance degradation in services. | Diagnosis & Action: Actionable paths like 'retry this' or 'reroute this' for specific failures. | Business Insight: Strategic reports highlighting growth, decline, or performance shifts. | Financial Truth: Audited statements and exception reports showing final reconciled balances. |
Two specific errors follow from mixing these up:
The first is assuming a successful API call means the payment succeeded. Adyen points out that a system can return an HTTP status 200 even if the payment was declined. In this situation, the transport layer succeeded because the connection worked and the computer processed the request, but the actual payment was still refused. Transport success, processing a request, and successfully collecting a payment are three completely different things. Only payment observability is built to track all three.
The second mistake is believing an operational status is final when it might still change. For instance, a timed-out authorisation could receive a delayed webhook hours later or show up in a settlement record, which completely changes the final result. Payment observability manages this uncertainty right away in real time. On the other hand, payment reconciliation figures out the absolute financial truth later on, after all the records are matched up. If you try to use reconciliation to make quick operational decisions, or if you use real-time observability to replace reconciliation, you will cause problems. Mixing these two systems up leads to incorrect retries, duplicate charges, and unreliable reporting.
Why do payment failures become harder to diagnose with multiple PSPs?
Each PSP has its own way of communicating what happened to a payment. They use different status models, different error vocabularies, different identifiers, different rules about when to send asynchronous responses, and different retention policies for the raw data. Without a layer that translates these into a shared language, an operations team working across three PSPs is effectively reading three different books written in three different dialects while trying to compare chapters.
The differences are concrete. Stripe typically separates issuer declines, blocked payments, and invalid API calls, surfacing different evidence for each category. When measuring authorisation performance, it is also best to look at unique declines separately from retry attempts. If you count every single attempt, including repeated retries of the same underlying failure, it skews your overall success rate. This distorted data can easily lead teams to make incorrect routing decisions.
For example, when an authorisation fails, Adyen returns a resultCode, a refusalReason, and a refusalReasonCode. It can also take the raw acquirer responses and translate them into standardized refusal reasons. PayPal Braintree, on the other hand, groups failures into processor-response classes and categorizes them as either hard or soft declines. It even warns teams that some of these processor responses can be completely ambiguous.
Each of these systems is well-documented and makes sense on its own. They simply use completely different taxonomies. A decline that Stripe classifies one way might appear under an entirely different label in Adyen's refusal codes. This happens not because either provider is wrong, but because their systems were built completely independently.
A merchant operating across multiple PSPs therefore needs two representations of every failure, held at the same time and never conflated:
- Raw evidence: the provider code, message, network code, advice code, HTTP status, timestamps, and references exactly as the PSP returned them.
- Canonical interpretation: a stable, versioned model that maps those raw signals into consistent categories used for reporting, alerting, routing decisions, and operational action.
You must never throw away the raw evidence just because you have a canonical label. As Adyen points out, schemes and issuers can change their raw response text without warning. This means a mapping that was accurate last month might need to be updated when new data arrives, and without the raw code, you have nothing left to re-examine. Furthermore, this raw data requires strict access controls. Stripe advises against showing sensitive decline details, like suspected fraud flags, directly to customers. Adyen gives the exact same advice regarding refusal reasons and raw responses.
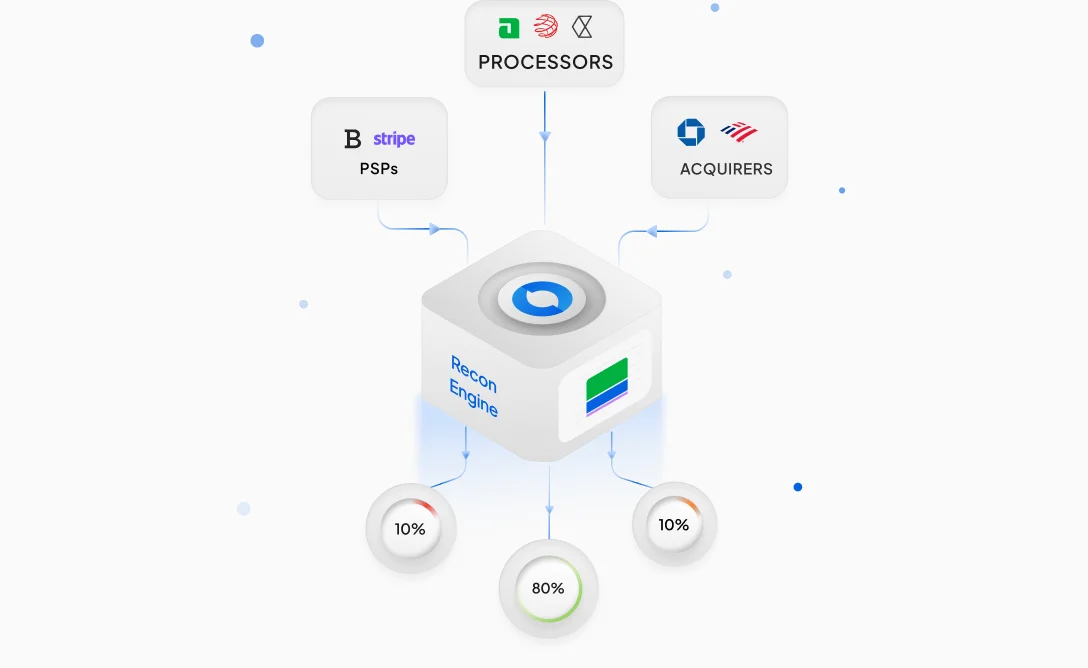
Juspay simplifies this complexity by acting as a unified orchestration layer. Instead of requiring your team to normalize disparate provider codes manually, Juspay ingests raw data from each PSP and maps it into a consistent, domain-native taxonomy. This normalization preserves the original forensic evidence for auditability while providing a stable, canonical model for alerting, reporting, and automated decision-making. By consolidating payment state and failure logic across all connected providers, Juspay enables teams to make routing and recovery decisions based on a single, clear view of the entire payment journey.
What canonical error taxonomy works across PSPs?
A useful canonical error taxonomy goes well beyond assigning a normalised label to a decline code. It needs to capture where in the payment journey the failure occurred, who was most likely responsible, what state the payment is currently in, how confident the system is in that interpretation, and what actions are still safe to take. Each of those dimensions serves a different purpose: some drive alerting, some inform routing decisions, some determine whether a retry is appropriate.
The canonical error model
| Dimension | Example values | Why it matters |
| lifecycle_stage | checkout, tokenisation, authentication, authorisation, capture, webhook, refund | Locates the failure in the payment journey |
| failure_origin | customer, merchant integration, orchestrator, fraud system, 3DS provider, PSP, acquirer, network, issuer | Identifies likely ownership without overstating certainty |
| canonical_category | invalid input, authentication failure, issuer decline, risk block, configuration error, provider technical error, unknown state, abandonment | Makes cross-provider comparison possible |
| canonical_reason | insufficient funds, expired credential, issuer unavailable, invalid merchant setup, 3DS challenge abandoned | Supports diagnosis and specific action |
| payment_state | failed, pending, authorised, reversed, unknown | Prevents uncertainty from being reported as a definitive failure |
| recoverability | query status, retry later, use another provider, authenticate, correct data, request another method, review, stop | Turns evidence into safe action |
| confidence | explicit, mapped, inferred, unknown | Makes ambiguity visible |
| raw_evidence | PSP code and message, network code, advice code, HTTP status, provider reference | Preserves forensic detail |
| business_context | amount, currency, method, issuer country, channel, entity | Measures impact and finds localised patterns |
| correlation | order ID, attempt ID, trace ID, PSP reference, network transaction ID, idempotency key | Reconstructs the journey and prevents duplicate action |
Let's discuss it with an example to see how the flow works in real life:
1. A customer is sitting on your checkout page. They type in their Visa card, click "Pay", and their bank rejects it because they typed their CVV code wrong.
2. The PSP spits out a messy, ugly computer response: {"event": "AUTH_FAIL", "sub_code": 882}.
3. Your Canonical Error Model intercepts that messy code, grabs its digital intake form, and looks at Row 1:
- It looks at the Dimension (lifecycle_stage).
- It looks at the Example Values dropdown menu, skips checkout, skips tokenisation, and selects authorisation.
- Why it matters: Because tomorrow morning, when the Head of Payments looks at a pie chart of 10,000 failed transactions, they don't see 10,000 weird"sub_code: 882" messages. They see a clean slice of the pie that says: "42% of our failures happened at the Authorisation stage."
(And because of the "Why it matters" column, the Head of Payments instantly knows the diagnosis: "Ah, the checkout button works, the Apple Pay tokens work. But, our problem is strictly that the banks are turning our customers down at the very last second.")
Capturing these dimensions successfully establishes the diagnosis, but visibility without action has limited operational value. The ultimate test of a canonical error model is whether it allows a system to act autonomously. By distilling thousands of chaotic, provider-specific response codes into a finite list of canonical_categories, an engineering team can stop relying on human guesswork and start binding every standardized failure to a deterministic safe response. The matrix below maps out this exact logic, connecting each core failure category directly to its automated next step:
Canonical failure categories and their safe responses
| Category | Typical evidence | Default interpretation | Possible next action |
| Invalid customer or payment data | Invalid number, expiry, CVC, amount, or currency | Explicit input problem if the provider is specific | Correct the data or request another method |
| Authentication required or failed | 3DS required, challenge failed, authentication abandoned | Authorisation should not continue unchanged | Authenticate, step up, or let the customer retry |
| Issuer or account decline | Insufficient funds, restricted account, generic issuer refusal | Customer or account decision; confidence may be low | Ask for customer action, another method, or a later attempt |
| Risk or compliance block | Fraud rule, policy restriction, compliance refusal | Sensitive and often non-retriable | Use a generic customer message; review or stop |
| Merchant or integration configuration | Invalid merchant, unsupported capability, malformed field | Likely systemic if repeated across customers | Fix configuration or payload |
| Provider or network technical error | Timeout, 5xx, switch unavailable, latency spike | Potentially recoverable, but state may be uncertain | Query status before a safe reroute or retry |
| Customer cancellation or abandonment | Shopper cancelled, redirect closed, challenge expired | Incomplete customer-controlled journey | Resume or offer an alternative |
| Duplicate or idempotency conflict | Duplicate response, reused key, recent matching transaction | A prior outcome may already exist | Retrieve the previous state; do not retry blindly |
| Pending or state unknown | Delayed webhook, no final response, asynchronous method | Not a definitive failure | Wait, poll, query, or reconcile later |
| Unsupported operation | Payment method, currency, recurring flow, or feature unsupported | Eligibility or configuration issue | Use an eligible provider or payment method |
Why "hard decline" and "soft decline" are not enough
Most payments teams are familiar with the hard/soft distinction. Hard declines are permanent, while soft declines might succeed on a retry. This is a helpful starting point, but it only answers one basic question: should you retry? Even that answer is unreliable because it groups together totally different situations that require completely different responses.
Even with that nuance, the label alone still leaves a multi-PSP merchant without answers to the questions that actually decide what to do next:
- Is the current payment state actually known, or is it still uncertain?
- Is the same card credential usable on another attempt?
- Should the next attempt go to the same PSP, or a different one?
- Does the customer need to complete an authentication step first?
- Does the customer need to correct their payment details?
- Do the card network's retry rules permit another attempt at all?
- Has a previous attempt on this order already succeeded somewhere downstream?
A single "soft decline" can hide several different problems at once. For example, an insufficient-funds response and an authentication-required response are both technically retriable. However, one requires waiting to try again later, while the other requires a step-up challenge. If you retry the second problem the exact same way you retried the first, it will simply fail again. This is why the canonical model treats recoverability as its own separate dimension. It makes a tailored decision for each transaction based on the payment's current state, the network's rules, and the history of what has already been attempted. The decline code is just one piece of information used to make that choice; it was never meant to be the decision itself.
What should an end-to-end payment trace show?
A payment trace is the ordered timeline of everything that happened to an order. It follows the journey from the moment a customer initiates checkout all the way to the final known outcome. Along the way, it records every single attempt, routing decision, authentication step, provider call, webhook, and status query.
OpenTelemetry defines a span as a unit of work or operation, capturing identifiers, timestamps, attributes, events, links, and status. Payment tracing builds on that foundation by adding domain semantics to each span: which stage of the payment journey it represents, which provider received the request, what that provider returned, and whether the outcome is definitively known or still pending.
A synthetic payment trace:
The following example shows why the unknown is a legitimate and important payment state and why collapsing it into failed causes problems.
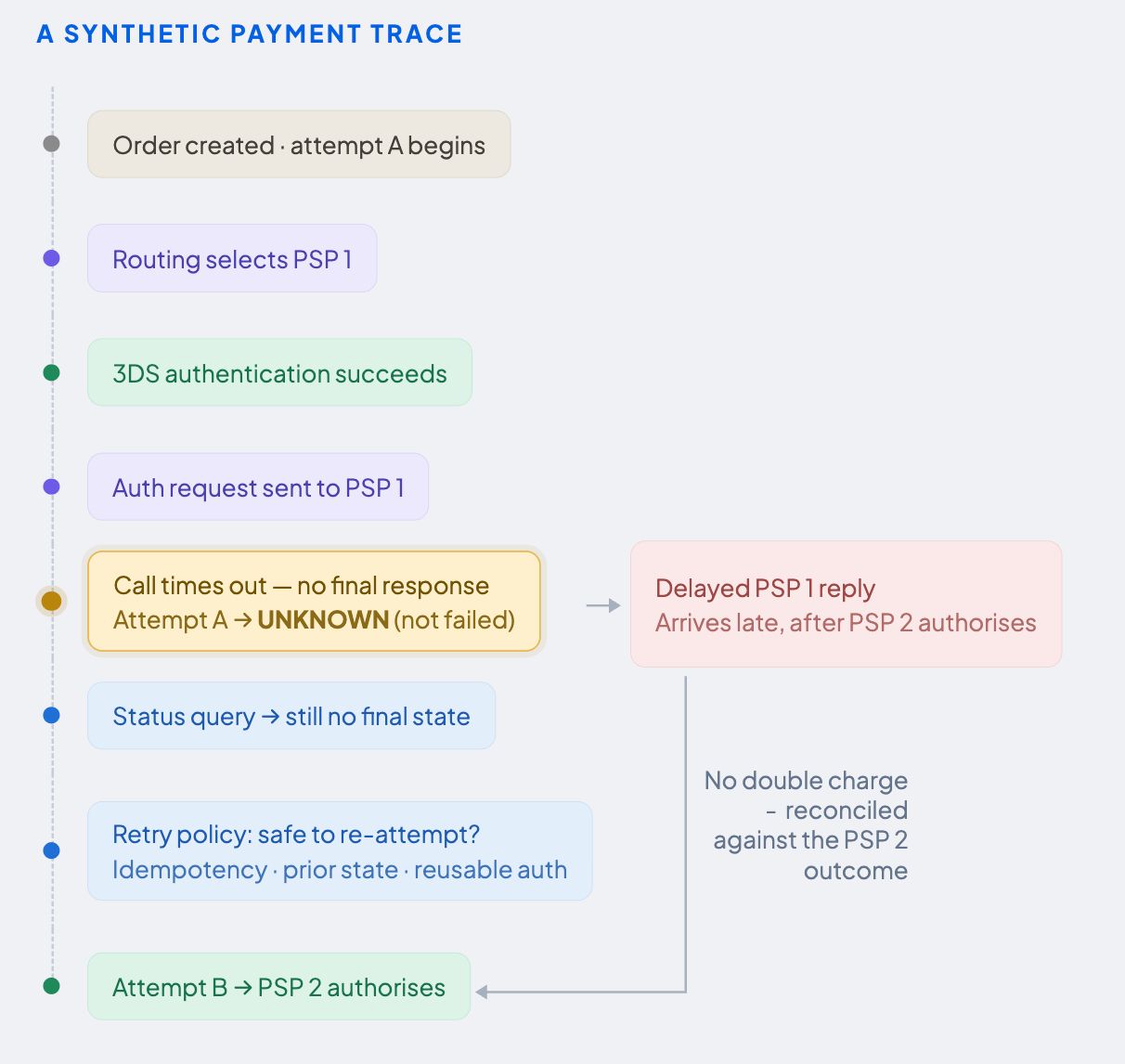
- An order is created.
- Payment attempt A begins.
- The routing layer selects PSP 1.
- 3DS authentication succeeds.
- PSP 1 receives the authorisation request.
- The merchant-facing call times out before a final response arrives.
- The payment enters unknown - not failed.
- A provider status query is issued; it returns no final state yet.
- The retry policy evaluates idempotency, the state of previous attempts, whether authentication can be reused, and what provider guidance says.
- An eligible second attempt is sent to PSP 2.
- PSP 2 authorises the payment.
- A delayed response from PSP 1 arrives and is checked against the PSP 2 authorisation to confirm there is no duplicate charge.
Step seven is where many systems go wrong. A timeout only describes what the calling system experienced, meaning it simply failed to receive a response within the expected time window. It says nothing about what happened on the provider's side. PSP 1 may have processed the authorisation successfully before the connection dropped. A system that marks this attempt failed and immediately fires a retry is acting on an assumption, not evidence, and risks charging the customer twice.
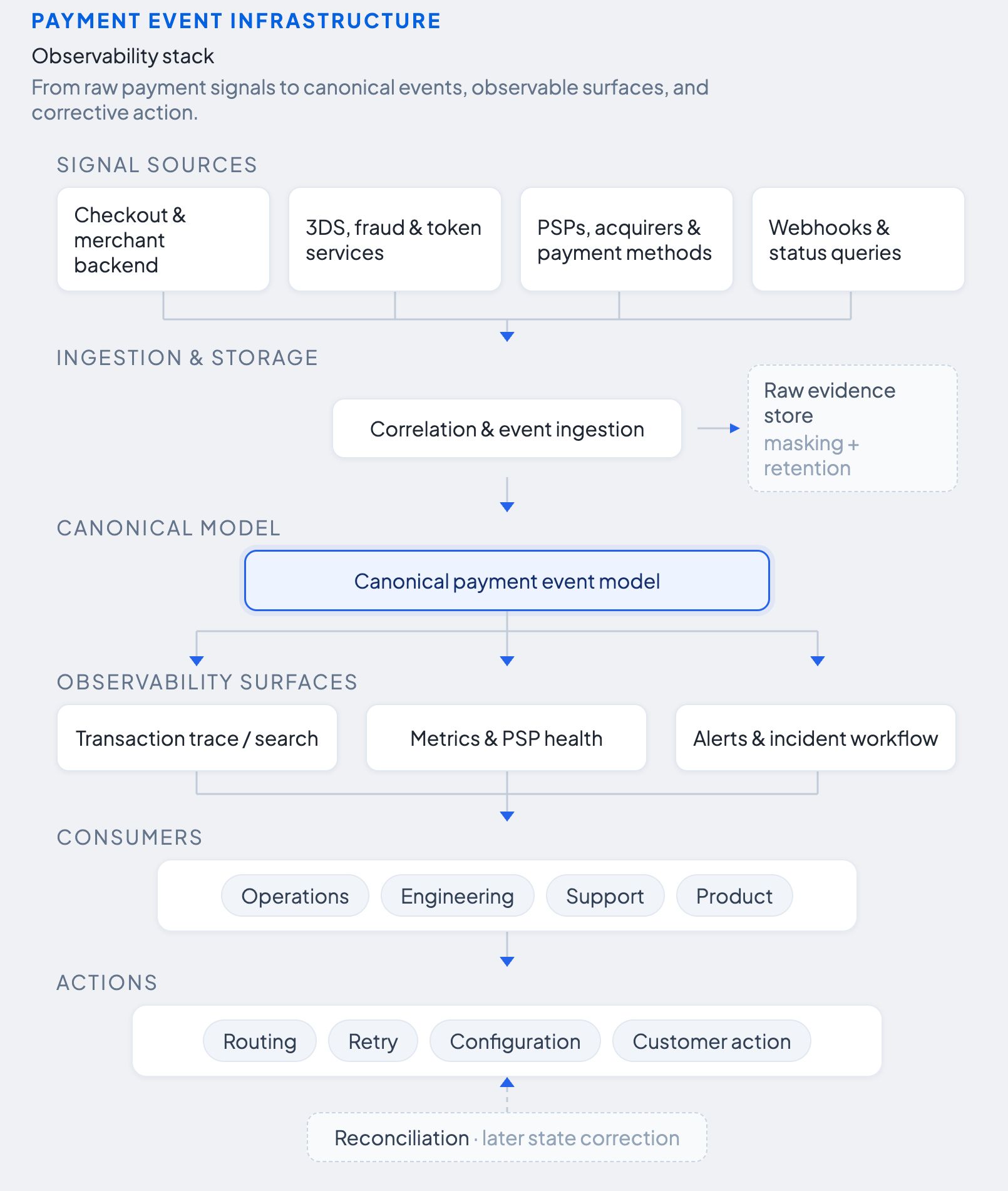
What does a complete payment-observability stack contain?
A complete payment-observability stack is not a single tool . It is a set of capabilities that work in sequence. Signals are collected from every system that touches a payment, correlated into a single journey, stored as both raw evidence and a canonically interpreted model, and then surfaced through traces, metrics, alerts, and incident workflows that lead to action.
Observability stack layers
| Layer | Required capability | What fails if it is missing |
| Signal collection | Client and server events, authentication, routing, PSP calls, webhooks, status queries | Blind spots appear between systems |
| Correlation | Stable IDs across order, payment, attempt, provider, and network | One journey cannot be reconstructed |
| Raw evidence | Original codes, messages, timestamps, references, masked payload metadata | Mapping errors cannot be audited |
| Canonical semantics | Versioned stage, origin, category, state, recoverability, confidence | Provider comparisons become misleading |
| Trace and search | Ordered timeline with transaction drill-down | Teams jump among PSP portals and support tickets |
| Metrics | Outcomes, stage latency, error mix, pending age, retry results | Dashboards show volume without explaining it |
| Segmentation | PSP × method × operation × geography × issuer × channel | Partial failures disappear in averages |
| Alerting | Threshold, change, anomaly, persistence, and business-impact rules | Detection is late or noisy |
| Incident workflow | Owner, severity, mitigation, communication, review | Signals do not become action |
| Governance | Role-based access, masking, retention, mapping history, configuration audit | Sensitive data and changes become untraceable |
| Export | API, webhook, file, and business-intelligence integration | Operational data remains trapped in one dashboard |
Which metrics reveal PSP degradation?
The challenge with PSP-health metrics is that aggregate numbers hide the problems that matter. A provider's overall authorisation rate can look fine while one issuer country, one payment method, or one authentication path is quietly failing. Useful metrics must be calculated at the segment level and measured against a relevant baseline, rather than simply being averaged across all traffic.
Outcome metrics
- Order conversion rate
- Payment-attempt authorisation rate
- Unique decline rate
- Failure mix by canonical category
- Pending and unknown-state rate
- Reversal or duplicate-protection events
One important distinction: order conversion and attempt authorisation rate should never be conflated. Retries can improve the number of orders that eventually complete while simultaneously increasing the count of failed attempts. Stripe explicitly recommends measuring unique declines separately from retry attempts to get an accurate view of true authorisation performance. Combining them makes the rate look better than it is and masks the underlying failure pattern.
Performance metrics
- End-to-end latency percentiles
- Authentication, orchestration, and PSP stage latency
- Timeout rate
- Webhook delivery lag
- Provider status-query lag
Stage-level latency matters because a simple end-to-end number cannot tell you which participant caused the slowdown. Seeing that a transaction took 4.2 seconds is unhelpful. However, knowing that 3.8 of those seconds were spent waiting for a PSP response, while authentication and orchestration were both fast, points your team directly to the bottleneck. A 2025 study on distributed instant-payment infrastructure made this exact argument. It noted that traditional IT monitoring fails to connect raw technical data to actual business visibility, and stage-based timing is the only way to bridge that gap.
Recovery and data-quality metrics
- Retry eligibility and recovery rate
- Failover outcomes
- Customer-action recovery rate
- Percentage of failures with explicit, mapped, inferred, or unknown cause
- Missing provider-reference rate
- Uncorrelated-event rate
- Unmapped-response rate by taxonomy version
How should PSP health be segmented?
The goal is not to add every possible filter. It is to find the smallest segment that isolates a meaningful failure without producing noise so granular it becomes unreliable. A useful starting set of segmentation dimensions:
- PSP or acquirer
- Payment method and operation type
- Issuer country or permitted BIN grouping
- Merchant entity and merchant account
- Currency and amount band
- Authentication path taken
- Channel or device
- Customer-initiated versus merchant-initiated payment
- New versus stored credential
- Processing region and endpoint
How should payment alerts identify business impact?
A raw error-count threshold alerting when failures cross some fixed number is a poor alert condition because it fails in two opposite directions.
First, it misses failures that are critical but low in volume. For example, if an enterprise merchant's checkouts suddenly break entirely, those few hundred errors will be drowned out by millions of healthy transactions elsewhere. The global count barely moves, but the merchant experiences a total outage. The threshold stays quiet while real revenue is lost.
Second, it fires on failures that are high in volume but completely harmless. During a normal sales peak, overall traffic rises, meaning the absolute number of declines naturally rises with it. Even when the actual failure rate is completely steady, the raw count crosses the line and pages your team for an incident that does not exist.
The underlying flaw is identical in both scenarios. A basic count only measures how many total failures occurred; it cannot tell you whether the rate, the specific segment, or the actual business impact has changed.
Useful payment alerts combine a meaningful rate change with a minimum volume floor, a persistence window to filter transient noise, a defined affected segment, and an estimate of the business impact. That combination ensures teams are alerted to things that matter, not just things that are technically anomalous.
| Alert | Conditions | Likely owner | First diagnostic |
| PSP authorisation degradation | Success-rate drop against a segment baseline, minimum attempts, sustained window | Payments operations | Compare failure mix, latency, and alternate PSP |
| Latency and timeout spike | p95 or p99 rise with increased unknown states | Engineering and provider owner | Inspect stage timing and provider endpoint |
| Authentication failure increase | Challenge or technical failure rises by issuer, device, or region | Authentication owner | Inspect 3DS results and customer actions |
| Unknown-state backlog | Pending age or unknown count breaches a threshold | Payment operations | Query provider status and verify webhook delivery |
| Merchant configuration regression | Validation or configuration failures rise after a change | Integration owner | Compare release, merchant account, payload, and mapping version |
| Error-taxonomy drift | Unknown or unmapped responses increase | Payments platform team | Review raw codes before changing mappings |
Every incident record should retain the affected segment, first observed time, estimated order impact, canonical failure mix, evidence links, owner, mitigation steps taken, any configuration changes made, recovery time, and post-incident actions. Without that record, the same incident tends to recur.
How do you find the root cause of a failed payment?
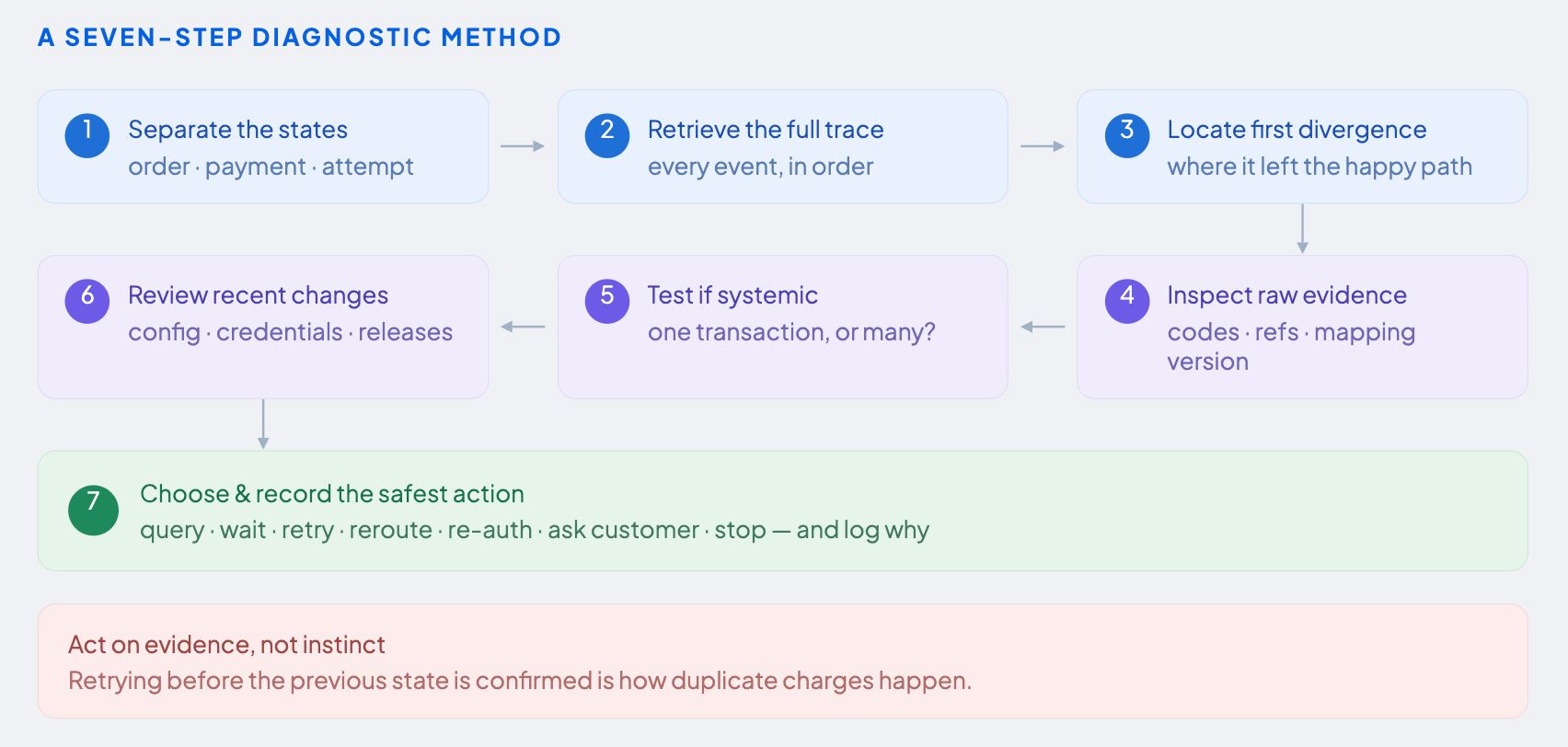
The instinct during a payment failure is to act quickly immediately by rushing to retry, reroute, or escalate the transaction. However, taking action before the evidence is completely clear is exactly how incorrect retries and duplicate charges occur. The correct approach is deliberate and methodical. Your system must first reconstruct what actually happened, pinpoint exactly where the journey went off track, and determine whether the problem is isolated or systemic. Only then choose an action.
A seven-step diagnostic method
1. Separate the states. Confirm the order state, payment state, and each attempt state independently. These can easily drift apart; for example, a payment might still be stuck in "pending" even though the e-commerce platform already marked the order as complete.
2. Retrieve the full trace. Pull the entire sequence of events from start to finish. This must include authentication events, routing decisions, PSP calls, webhooks, status queries, and any reversals. The full chronological order matters just as much as the individual data points.
3. Locate the first divergence. Find the exact moment this transaction's journey split away from the path of a normal, successful transaction in that same segment. That fork in the road is your primary investigation site.
4. Inspect raw evidence. Check the provider's raw response codes, error messages, references, and timestamps. Pay close attention to the canonical mapping version in use. A simple mapping error can accidentally make a temporary, recoverable failure look like a permanent rejection.
5. Test whether the problem is systemic. Look sideways. If the exact same failure pattern is suddenly appearing across multiple customers or checkouts in the same segment, you are likely looking at a provider outage, an issuer block, or a broken configuration rather than an isolated fluke..
6. Review recent changes. Check your routing rules, merchant credentials, 3DS policies, provider endpoints, recent code releases, and taxonomy updates. The vast majority of live payment incidents are the direct result of a recent system update.
7. Choose and record the safest action. Query status, wait for a webhook, retry, reroute, trigger authentication, ask the customer to correct their details, request another payment method, or stop. Whichever path the system takes, explicitly log the chosen action and the evidence that justified it.
How do you distinguish a PSP outage from an issuer decline spike?
These two situations can look similar on a high-level dashboard. In both cases, authorisation rates drop and alerts fire. However, they have completely different root causes and require completely different operational responses. The fine-grained signals captured inside the trace are what allow your system to tell them apart.
| Signal | More consistent with PSP or acquirer degradation | More consistent with issuer or account declines |
| API errors | 5xx, connection errors, timeouts | Often normal transport responses |
| Latency | Broad or endpoint-specific increase | Usually stable |
| Failure mix | Technical, unavailable, unknown state | Insufficient funds, restricted, generic issuer refusal |
| Concentration | PSP, operation, endpoint, region | Issuer, BIN group, customer or account segment |
| Alternate PSP | Same segment improves elsewhere | Same issuer segment may remain weak |
| Provider reference | May be missing on early failure | Usually present after processing |
None of this is conclusive on its own. A provider can map an issuer problem using technical error codes, making it look like a PSP issue. A merchant configuration error can produce patterns that resemble a provider outage. The raw response and the full trace remain the most reliable evidence.
What should happen after a timeout?
A timeout means the calling system did not receive a response within the expected window. It does not mean the payment failed. Before taking any further action, use the PSP reference, idempotency key, status API, webhook history, and prior attempt record to determine whether the authorisation may have already completed on the provider's side.
The safe sequence after a timeout:
- Move the attempt into an "unknown" or "pending" state. Never mark a timed-out transaction as failed right away.
- Query the provider for an authoritative status, or wait for the expected webhook.
- Apply a bounded waiting policy. Give the provider a reasonable window of time to answer, but never let your system wait indefinitely.
- Trigger a retry or a reroute only after the previous state is definitively confirmed, and only if the payment network's rules permit another attempt.
- Continue monitoring for delayed events from the original provider. These late signals can easily arrive after a second attempt has already been processed, which instantly introduces the risk of a duplicate charge.
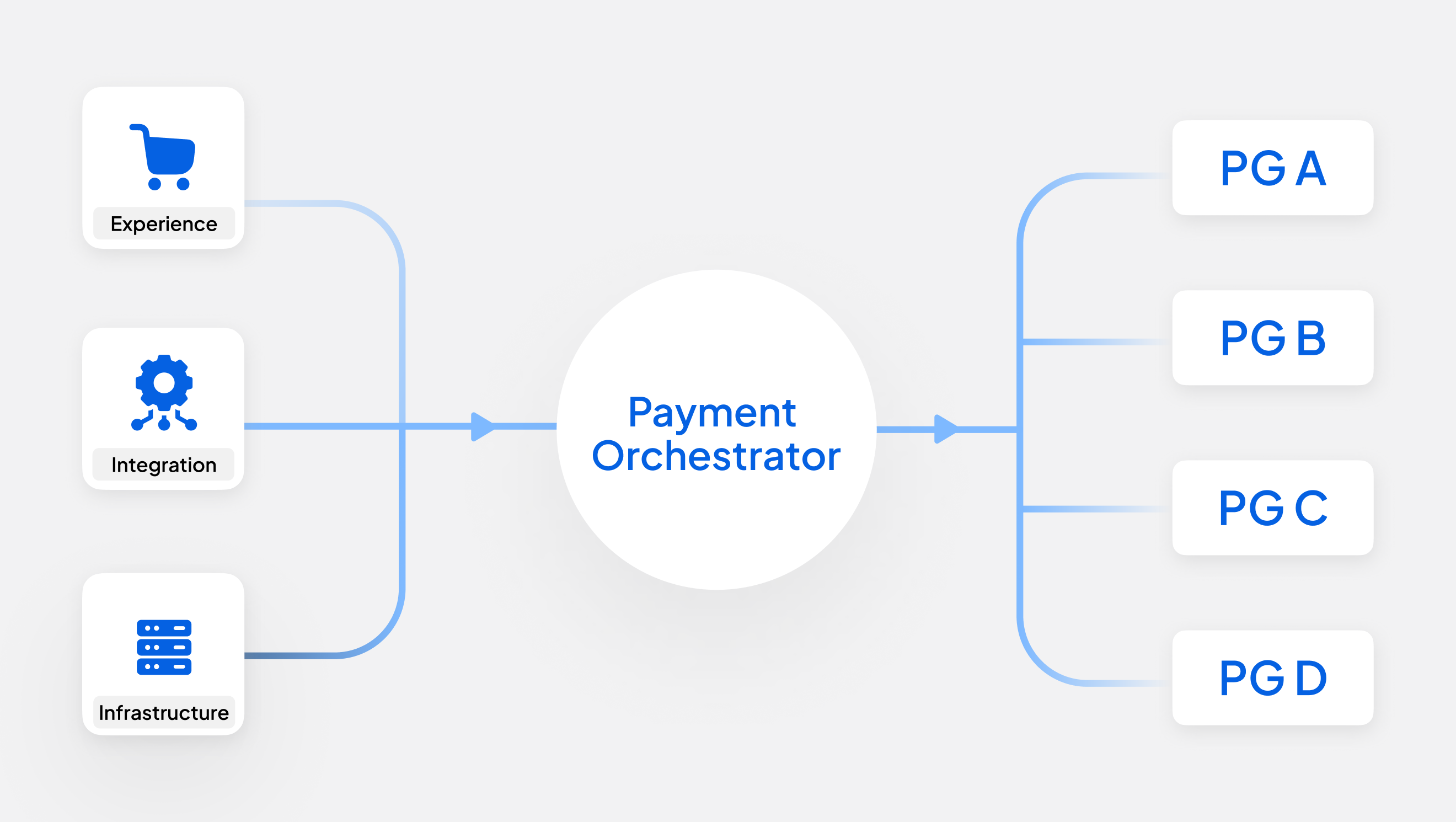
What should enterprises require from a payment-orchestration platform?
Routing capability is the most visible feature of a payment-orchestration platform, allowing your system to move transactions across different PSPs based on cost, performance, or availability. However, operational visibility is just as important. Imagine a platform that can route traffic across five providers, but cannot explain why transactions are failing on three of them, or whether a timeout on the fourth is actually resolved. This blind spot forces your operations team to do the diagnostic work manually. They are left logging into separate PSP portals, reconciling incompatible data models, and reconstructing payment journeys entirely by hand.
When evaluating platforms, use these questions to assess observability capability:
- Can one order view display every payment attempt and every provider transition in sequence?
- Are both the raw provider response and the normalised interpretation available for each attempt?
- Is the canonical taxonomy version visible and auditable — so teams can tell whether a mapping change affected historical data?
- Can users clearly distinguish between transport-level, processing-level, payment-level, and financial-level states?
- Can health metrics be segmented by PSP, payment method, operation type, market, issuer, merchant account, and authentication path?
- Can alert conditions combine rate changes, absolute counts, transaction value, persistence duration, minimum traffic volume, and deviation from a segment baseline?
- Are pending and unknown treated as legitimate, first-class outcomes — not defaulted to failed?
- Are routing decisions and retry logic explainable in the trace, not just in configuration documentation?
- Are user actions and configuration changes logged with timestamps and attribution?
- Can masking, data retention, role-based access, and export behaviour be configured per deployment?
- Can a simulated provider degradation be detected in acceptance testing before it reaches production?
How does orchestration improve payment observability?
An orchestration layer occupies a unique position in the payment stack: it sees the same merchant's transactions across every connected provider, using a consistent contract. That position makes it structurally well-suited to observability work that would otherwise require stitching together data from separate PSP portals with incompatible formats.
Because the orchestrator routes every attempt, it can correlate them under a single order. Because it receives responses from all providers, it can apply a consistent canonical model across all of them. Because it manages retry and reroute logic, it can make those decisions visible and auditable rather than having them happen silently inside a single provider's SDK.The result is that an investigation that used to take an operations team forty-five minutes across three browser tabs can now be diagnosed in three seconds inside one.
In practice, this is why Juspay's payment-orchestration layer connects to more than 300+ PSPs and local payment methods and serves businesses across 150+ countries. Operating at this massive scale means observability cannot be bolted on at the end as a mere reporting afterthought. Instead, it is built directly into the core control plane. It runs actively inside the live payment flow, working right alongside vital functions like routing, authentication, tokenisation, retries, and provider management.
Juspay processes more than 300+ million daily transactions, over USD 1 trillion+ in annual payment volume, and handles 50,000 peak transactions per second with 99.999% uptime. At that scale, true observability shifts the focus from merely counting errors to instantly explaining them. Operations teams need consistent semantics, transaction-level evidence, and a clear path from observation to action.
Key Takeaways
- Payment observability explains transaction outcomes; infrastructure monitoring reports system behavior. Treating the two as the same thing leads directly to incorrect retries, duplicate charges, and unreliable reporting.
- Preserve raw provider responses alongside a versioned canonical interpretation. Never overwrite or discard the raw code to save space. It is the exact evidence your team needs the moment a mapping turns out to be wrong.
- Model pending and unknown as first-class payment states. A network timeout does not prove a payment failed. Acting as if it did is the single most common cause of duplicate charges in multi-PSP environments.
- Build traces around business objects, not just server requests. Your timeline must link together the order, the payment, the individual attempts, provider references, authentication steps, webhooks, and idempotency keys.
- Segment PSP health by payment method, operation, market, issuer, and merchant account. Partial degradation is completely invisible inside provider-wide averages.
- Treat recoverability as a dynamic policy decision. It must be determined by evaluating the full picture of current evidence, rather than being treated as a fixed property of the decline code itself.
- Keep financial reconciliation in its own separate lane. While reconciliation establishes absolute truth after the fact, it is never a substitute for real-time operational observability.
Frequently Asked Questions
What is payment observability?
Payment observability is the ability to reconstruct a payment’s journey across every system that handled it, interpret each provider's responses consistently, detect failure patterns by segment, and determine the next safe action.
To do this, it weaves together standard logs, metrics, and traces with deep business context, payment-domain events, raw PSP evidence, and a shared canonical model.
While infrastructure monitoring simply tells you whether your servers are online, payment observability tells you what actually happened to a specific transaction and exactly what to do about it.
How is payment observability different from infrastructure monitoring?
Infrastructure monitoring tells you whether your services, APIs, and queues are healthy. Payment observability tells you what actually happened to an order or payment attempt. It tracks the complete picture, covering authentication, routing, provider responses, customer actions, asynchronous events, and whether a failure is recoverable.
Ultimately, infrastructure telemetry is an input to payment observability, not a replacement for it. Payments can easily fail while every single infrastructure metric looks completely normal.
How do you normalise decline codes across multiple PSPs?
Preserve each PSP's raw response exactly as received, then map it into a versioned model that captures the lifecycle stage, likely origin, canonical category, current payment state, recoverability, confidence level, and recommended next action. Never discard the raw code in favour of the normalised label. Provider mappings and issuer messages can change without notice, so you need the original evidence to audit and update interpretations over time.
What should a payment transaction trace include?
A payment trace should include the merchant order ID, payment and attempt IDs, routing decision, authentication events, PSP and network references, raw provider responses, timestamps, stage latency, webhooks, status queries, retries, reversals, idempotency key, and the final known state. OpenTelemetry span links are useful for connecting synchronous checkout events with later asynchronous ones, such as delayed webhooks or out-of-session payment completions.
When is it safe to retry a failed payment?
Triggering a retry is safe only when two strict conditions are met: the previous attempt's state has been positively confirmed rather than simply assumed, and the system's failure policy explicitly permits another attempt.
This assessment must account for a careful checklist of data: the raw provider evidence, returned advice codes, idempotency keys, authentication status, card network retry restrictions, and any prior attempts on that same order. Weighing all of these clues together is the only way to protect the customer against the ultimate mistake of a duplicate charge.
Finally, if a transaction results in a network timeout or a missing webhook, the software must immediately place the attempt into an unknown state. From there, it is required to fire a direct status query to the provider before any retry decision is actually made.
How do you detect a PSP outage?
To reliably detect PSP degradation, your system must monitor a complete set of vital signs: the overall authorisation rate, the error mix sorted by canonical category, latency percentiles, the timeout rate, raw traffic volume, the pending state age, and the provider reference quality.
However, looking at a giant heap of data will hide the truth. You must analyze these metrics segmented across specific slices of your business: by payment method, operation type, market, issuer, merchant account, and individual endpoint.
Once you spot an affected cohort, immediately cross-reference it. Compare the failing group against its own normal historical baseline, and check it against the exact same segment being processed through alternate PSPs. This triangulation provides an instant, clear diagnosis. If a drop in success hits one provider but leaves alternate providers on that exact same issuer segment completely untouched, you are almost certainly looking at a provider issue rather than an issuer failure.
Is payment observability the same as reconciliation?
No. Payment observability diagnoses operational states and failures in real time or close to it. Reconciliation is a later process that compares orders, processor records, settlements, fees, refunds, disputes, and bank credits to establish whether the financial records are consistent and accurate. A delayed settlement file or webhook may arrive and correct an earlier uncertain operational state , which is precisely why the two must be kept separate and sequential, not merged.
How does Juspay provide visibility across multiple PSPs?
Juspay operates an orchestration layer across 300+ PSPs and local payment methods and serves businesses across 150+ countries. Because it sits between the merchant and all connected providers, it can correlate attempts under a single order, apply consistent canonical semantics across all provider responses, and surface routing and retry decisions in a single operational view without requiring teams to log into separate PSP portals and manually reconcile incompatible data.